Gene Structure: Family of genes:
Gene is the unit of heredity (DNA or RNA) with a structure and function. Genes are duplicated, slightly modified in time and inherited, over a time course of evolution, developed into gene family or a family of genes. A gene may exist in multiple copies with certain subtle variations, some may be active some may be inactive as pseudo genes or cryptic genes. A gene family is a group of genes that share important characteristics. In many cases, genes in a family share a similar sequence of DNA building blocks (nucleotides). These genes provide instructions for making products (such as proteins) that have a similar structure or function. In other cases, dissimilar genes are grouped together in a family because proteins produced from these genes work together as a unit or participate in the same process.
Genes belonging to multiple alleles fall into a family of genes. They may be clustered in a region or dispersed in the genome. The members of this gene family may express at different stages of development and some may remain silent. Often genes that are involved in a particular structure or function can be deemed as a family of genes, ex. DNA pol and RNA pol involved in DNA replication and transcription. There are Gene families-allelic family, functional families and Protein family of genes.
Basic structural features of Genes:
Basically, it consists of a segment of genetic material-DNA (in most) or RNA (some viruses). It is associated with specific proteins; this forms into unit of heredity; it replicates, performs functions by producing specific RNAs and proteins. It is a unit, means a length of the genetic material, which replicates and performs a specific function by producing a specific protein, It undergoes mutations in time and creates variations. The number of genes per organism varies from organism to organism.
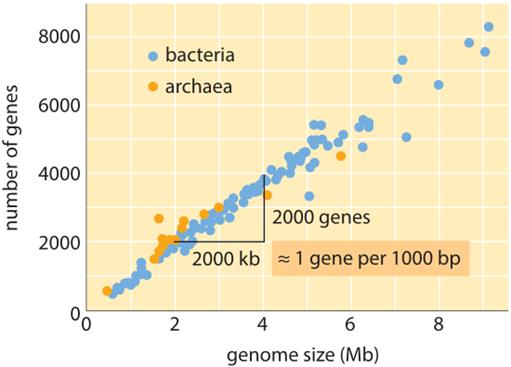

http://book.bionumbers.org/
A comparison between the number of genes in an organism and a naïve estimate based on the genome size divided by a constant factor of 1000bp/gene, i.e. predicted number of genes = genome size/1000. One finds that this crude rule of thumb works surprisingly well for many bacteria and archaea but fails miserably for multicellular organisms. http://book.bionumbers.org/.
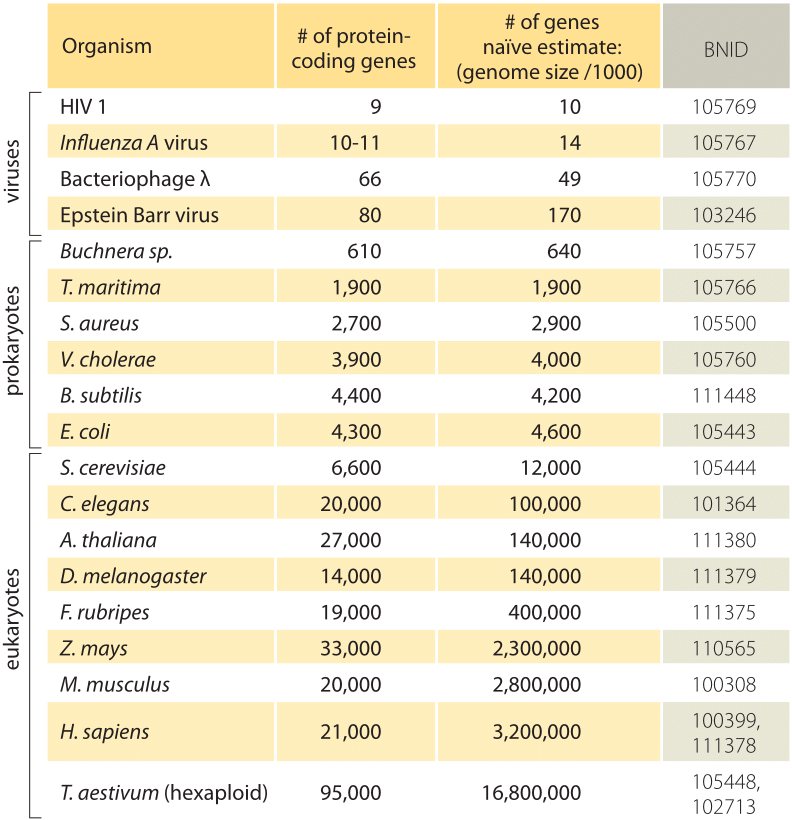
How Many Protein-Coding Genes Are in That Genome?
Interestingly, the same "remarkable lack of correspondence" can be noted when discussing the relationship between the number of protein-coding genes and organism complexity. Scientists estimate that the human genome, for example, has about 20,000 to 25,000 protein-coding genes. Before completion of the draft sequence of the Human Genome Project in 2001, scientists made bets as to how many genes were in the human genome. Most predictions were between about 30,000 and 100,000. Nobody expected a figure as low as 20,000, especially when compared to the number of protein-coding genes in an organism like Trichomonas vaginalis. T. vaginalis is a single-celled parasitic organism responsible for an estimated 180 million urogenital tract infections in humans every year. This tiny organism features the largest number of protein-coding genes of any eukaryotic genome sequenced to date: approximately 60,000.
In fact, compared to almost any other organism, humans' 25,000 protein-coding genes do not seem like many. The fruit fly Drosophila melanogaster, for example, has an estimated 13,000 protein-coding genes. Or consider the mustard plant Arabidopsis thaliana, the "fruit fly" of the plant world, which scientists use as a model organism for studying plant genetics. A. thaliana has just about the same number of protein-coding genes as humans—actually, it has slightly more, coming in at about 25,500. Moreover, A. thaliana has one of the smallest genomes in the plant world! It would seem obvious that humans would have more protein-coding genes than plants, but that is not the case. These observations suggest that there is more to the genome than protein-coding genes alone.
As shown in Table 1 (adapted from Van Straalen & Roelofs, 2006), there is no clear correspondence between genome size and number of protein-coding genes—another indication that the number of genes in a eukaryotic genome reveals little about organismal complexity. The number of protein-coding genes usually caps off at around 25,000 or so, even as genome size increases.
Table 1: Genome Size and Number of Protein-Coding Genes for a Select Handful of Species
|
Estimated Total Size of Genome (bp)* |
Estimated Number of Protein-Encoding Genes* |
|
|
Saccharomyces cerevisiae (unicellular budding yeast) |
12 million |
6,000 |
|
Trichomonas vaginalis |
160 million |
60,000 |
|
Plasmodium falciparum (unicellular malaria parasite) |
23 million |
5,000 |
|
Caenorhabditis elegans (nematode) |
95.5 million |
18,000 |
|
Drosophila melanogaster (fruit fly) |
170 million |
14,000 |
|
Arabidopsis thaliana (mustard; thale cress) |
125 million |
25,000 |
|
Oryza sativa (rice) |
470 million |
51,000 |
|
Gallus gallus (chicken) |
1 billion |
20,000-23,000 |
|
Canis familiaris (domestic dog) |
2.4 billion |
19,000 |
|
Mus musculus (laboratory mouse) |
2.5 billion |
30,000 |
|
Homo sapiens (human) |
2.9 billion |
20,000-25,000 |
* There may be other estimates in the literature, but most estimates approximate those listed here.
While the majority of emphasis has been placed on protein-coding genes in particular, scientists have continued to refine their definition of what exactly a gene is, partly in response to the realization that DNA encodes more than just proteins. For instance, in a study of the mouse genome, scientists found that more than 60% of this 2.5 billion bp genome is transcribed, but less than 2% is actually translated into functional protein products (FANTOM Consortium et al., 2005). Within this article, however, the discussion focuses on protein-coding genes, unless otherwise stated. https://www.nature.com/
Main components of Human genome:
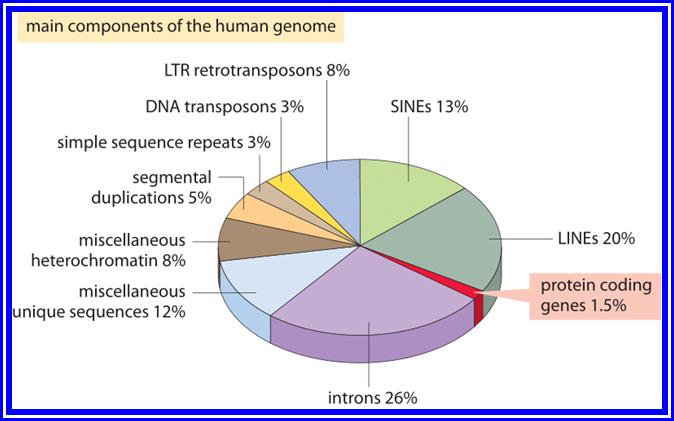
The different sequence components making up the human genome. About 1.5% of the genome consists of the ≈20,000 protein-coding sequences which are interspersed by the non-coding introns, making up about 26%. Transposable elements are the largest fraction (40-50%) including for example long interspersed nuclear elements (LINEs), and short interspersed nuclear elements (SINEs). Most transposable elements are genomic remnants, which are currently defunct. (BNID 110283, Adapted from T. R. Gregory Nat Rev Genet. 9:699-708, 2005 based on International Human Genome Sequencing Consortium. Initial sequencing and analysis of the human genome. Nature 409:860 2001.) http:// book.bionumbera.org,https://www.slideshare.net
During the course of evolution, spanning several billions of years, the genes might have gone through duplication and certain degree of changes in their sequences, but not drastically. Some of those, which have lost functions, are called pseudo genes. Some of the related genes form a kind of super family.
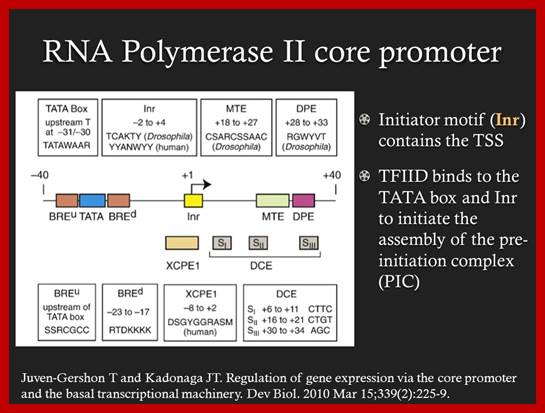
These diagrams represent just basic components of eukaryotic promoters, such as specific gene promoters and housekeeping gene promoters, transcribed by RNA pol II
http://slideplayer.com
Globin Genes:
Globin genes exist as clusters of alpha Globin and beta Globin family of genes. They are expressed at different stages of the development of the organism.
Alpha Globin:
They are organized in a cluster of 30kbp; they are organized in the following sequence.
----chi-I-psi-alpha--chi—psi-alpha-1---alpha-2—alpha-1-alpha-1—
Alpha clusters:
|
Gene |
Type |
Expression |
|||
Chi |
|
In embryo |
|||
|
Psi-alpha- |
Pseudo gene |
|
|||
|
chi |
|
|
|
||
|
Psi-alpha-1 |
Pseudo gene |
|
|||
|
Alpha-1 |
|
Fetus and adult |
|||
|
Alpha-2 |
|
Fetus and adult |
|||
|
Alpha-1 |
|
Fetus and adult |
|||
|
|
|
|
|||
|
|
|
|
|||
Beta clusters:
Beta clusters: organized in the following sequence. They are in a region of 50kbp locus, between the genes there are spaces, which are not transcribed, it holds good for both clusters. The table shows the expression of genes with time.
|
Gene |
Type |
Expressed in |
Epsilon |
- |
Embryonic stage |
|
G-gamma |
- |
Fetus stage |
|
A-gamma |
- |
Fetus stage |
|
Psi-beta0-1 |
Pseudo gene |
|
|
Delta |
- |
In adults |
|
Beta |
- |
In adults |
|
|
|
|
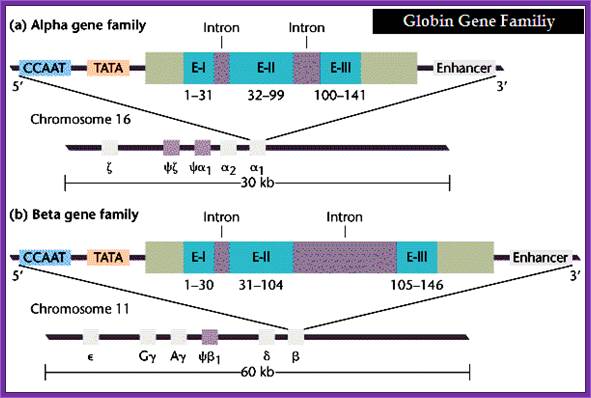
This line diagram depicts the organization alpha and beta globin gene families
Early Embryonic means: less than eight weeks.
Embryonic: means less than eight weeks of pregnancy, expressed genes are - Chi2, chi-2, gamma-2, alpha-2, and epsilon-2
Fetal means: 3-9 months, but expressed are alpha-2, gamma-2.
Adult means: from birth, but the expressed genes are alpha-2 delta-2, alpha-2, and beta2.
Chi and alpha are like alpha.
Epsilon, gamma, delta and beta are like beta.
Histone gene family:
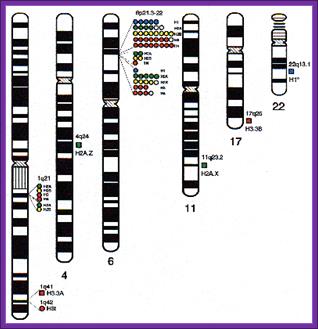
Histone genes exist not as single genes but as a family of genes and they are clustered together in certain loci of Human chromosomes.
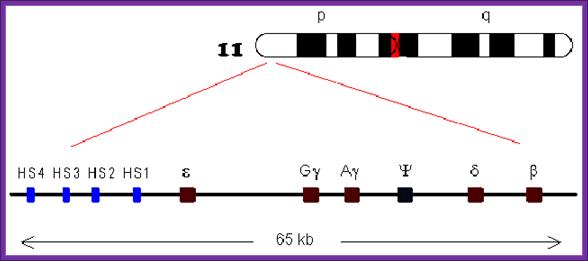
Clustering of Heat shock (Hs) and Globin genes on chromosome 11; http://www.web-books.com/
Sea urchin:
The repeat length is 6300 bp and the number of repeats is 300 in sea urchins and 600 in newts.

http://genome.cbs.dtu.dk/
Drosophila:
4800bp long and there are 100 repeats.

This diagram shows how histone genes as clusters organized as loci in chromosomes. http://genome.cbs.dtu.dk/
Humans: Human genome contains a family of Histone genes.
I--H1-->I--I--H3-->I---I<--H2b---I--I-->H2A-->I---I--H4->->
Yeasts: They contain two copies each of histone genes. Birds contain 10 to 20 repeats of each cluster. In mammals the number of repeats is 600 to 800.
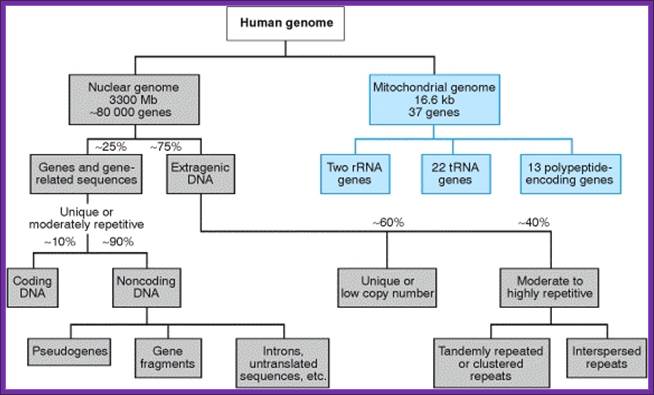
Classification of human genome into structural and functional forms
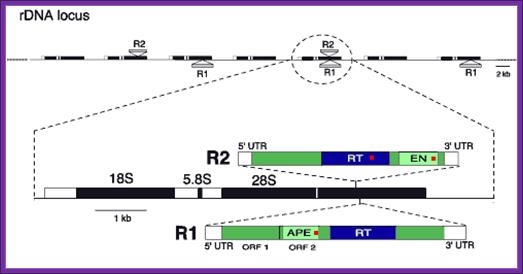
rRNA gene family; http://www.rochester.edu/
|
Some of the gene families |
Number of genes
|
Actin |
5-30 |
|
|
3-10 |
|
Keratin |
>20 |
|
Myosin (heavy chain) |
5-10 |
|
Protein kinase? |
10-100 |
|
Human Ig variable |
>500 |
|
Chick Ovalbumin |
3 |
|
Tubulin alpha and beta |
3-15 |
|
Visual pigment gene (human) |
4 |
|
Chick vitellogenin |
5 |
|
Insect egg shell protein |
- |
|
Silk fibroin (silk moth and fruit fly) |
50 |
|
Transplantation human antigen |
50-100 |
|
Globin genes |
|
|
|
|
|
Skin color, |
|
|
Hairs color |
|
|
Height, |
|
|
MHC class |
MHC I, II and III -200 genes |
|
Ig Family |
The Ig like domains can be classified as IgV, IgC1, IgC2, or IgI |
|
Homeobox, |
|
|
ABCA |
|
|
DNA Pol |
Prokaryotic, Archaea, eukaryotic |
|
RNA PoL |
Prokaryotic, Eukaryotic-RNAP I, II and III |
|
HSPs |
HSP 60, 70 and 90, HSP 90 has 17 or are more in human genome |
|
Ribosome Protein family |
60-70 |
|
tRNA family |
22-30 |
|
rRNA family |
PK and EK |
|
snRNA family |
5-8 |
|
Sigma factor family |
|
|
T and B cell receptors |
|
|
T cell receptors |
|
|
Cytokine /Lymphokines |
|
|
There are many protein families too |
|
|
Signal receptor s |
|
|
Motor |
|
|
Membrane transporters
|
|
|
Protein kinases and other kinases |
|
|
Phosphatase
|
|
|
Structural proteins |
|
|
Metallothionein |
|
|
Histone |
|
|
|
|
|
|
|
|
Distribution of Some Gene Families on the Chromosomes |
|||
|
Gene family |
Gene count |
Chromosomes |
Additional information |
|
3 |
2, 14, 19 |
identical protein sequences, many other related proteins |
|
|
3 |
1, 12, 17 |
||
|
4 |
1, 11, 14, 19 |
||
|
4 |
1, 6, 9, 19 |
also smaller related protein on chromosome 1 |
|
|
5 |
1 |
cluster spans about 205 kb, also pseudogene |
|
|
5 |
1, 7, 9, 12, 15 |
||
|
6 |
1, 2, 7, 10, 15, 17 |
also highly similar ACTBL2 and many other related proteins |
|
|
6 |
2, 4, 10 (3), 17 |
three genes on chromosome 10 not closely linked |
|
|
7 |
4 |
cluster spans about 365 kb |
|
|
11 |
16 |
cluster spans about 120 kb, also related genes / pseudogenes |
|
|
|
|
|
|
A gene family is a group of genes that share important characteristics. In many cases, genes in a family share a similar sequence of DNA building blocks (nucleotides). These genes provide instructions for making products (such as proteins) that have a similar structure or function.
In other cases, dissimilar genes are grouped together in a family because proteins produced from these genes work together as a unit or participate in the same process. Some of the genes found in duplicates and located on chromosomes, not on the same but can be on different chromosomes.
The following families, defined by the HUGO Gene Nomenclature Committee![]() are included in Genetics Home Reference.
are included in Genetics Home Reference.
- aaRS (aminoacyl tRNA synthetases)
- ABC (ATP-binding cassette transporters)
- ABHD (abhydrolase domain containing genes)
- ADAMTS (ADAMTS metallopeptidase with thrombospondin type 1 motif family)
- ALDH (aldehyde dehydrogenases)
- ALOX (arachidonate lipoxygenases)
- ATP (ATPase superfamily)
- bHLH (basic helix-loop-helix)
- BIRC (baculoviral IAP repeat-containing genes)
- blood group (blood group determining genes)
- CACN (calcium channels)
- CATSPER (cation channels, sperm associated)
- CD (CD molecules)
- CDH (cadherin superfamily)
- CHMP (chromatin modifying proteins)
- COLEC (collectins)
- COLPG (collagen proteoglycans)
- complement (complement system genes)
- CTS (cathepsins)
- CYP (cytochrome P450)
- DN (axonemal dyneins)
- DNAJ (DnaJ (Hsp40) homologs)
- FANC (Fanconi anemia, complementation groups)
- FOX (Forkhead box genes)
- FZD (frizzled homologs)
- GJ (gap junction proteins (connexins))
- GPC (glypicans)
- GPR (G protein-coupled receptors)
- HLA (histocompatibility complex genes)
- homeobox (homeoboxes)
- IFT (intraflagellar transport homologs)
- IL (interleukin and interleukin receptor genes)
- KCN (potassium channels)
- KIF (kinesins)
- KRT (keratins)
- LGIC (ligand-gated ion channels)
- mitochondrial respiratory chain complex (mitochondrial respiratory chain complex genes)
- NLR (nucleotide-binding domain and leucine rich repeat containing family)
- PAR (pseudoautosomal regions)
- PARK (Parkinson disease)
- PAX (paired box gene)
- PDI (protein disulfide isomerases)
- PG (proteoglycans)
- PTP (protein tyrosine phosphatases)
- RAB (RAB, member RAS oncogene family)
- RNF (RING-type zinc fingers)
- RPL (L ribosomal proteins)
- RPS (S ribosomal proteins)
- SCN (sodium channels)
- SDR (Short chain dehydrogenase/reductase superfamily)
- serine/threonine phosphatases (serine/threonine phosphatases)
- SERPIN (serine (or cysteine) proteinase inhibitors)
- SLC (solute carriers)
- SLRR (small leucine-rich repeat family)
- SMAD (SMAD, mothers against DPP homologs)
- SMC (structural maintenance of chromosomes proteins)
- SOX (SRY (sex determining region Y)-box genes)
- TBX (T-box gene family)
- TNFRSF (tumor necrosis factor receptor superfamily)
- TNFSF (Tumor necrosis factor (ligand) superfamily)
- TRIM (tripartite motif-containing)
- TRP (transient receptor potential cation channels)
- UBA (ubiquitin-like modifier activating enzymes)
- UGT (UDP glucuronosyltransferases)
- USP (ubiquitin-specific peptidases)
- WNT (wingless-type MMTV integration site family)
- ZCCHC (zinc fingers, CCHC domain containing)
- ZFYVE (zinc fingers, FYVE-type)
- ZNF (zinc fingers, C2H2-type).